分类算法 |
您所在的位置:网站首页 › shadow price英文定义 › 分类算法 |
分类算法
|
一、定义
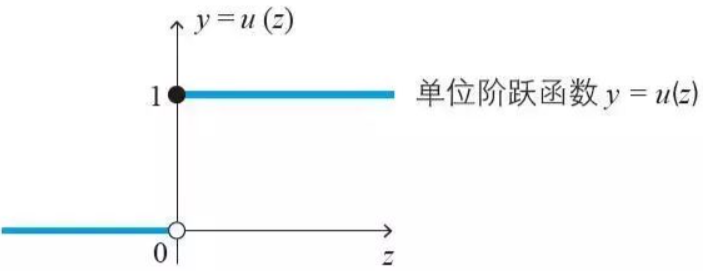
逻辑回归是一种广义线性回归模型,主要用于二分类问题(也可以用于多分类),具有简单、可并行化、解释性强的特点,目前在各个领域使用的都非常频繁。逻辑回归的本质是假设数据服从伯努利分布,然后使用极大似然估计做参数的估计(类似最小二乘估计),再通过Sigmoid函数将预测值映射到(0,1)范围内,根据预测值的所在区间进行分类。 二、模型理论极大似然估计 极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。 特征分析: 总结起来,最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。 Sigmoid函数 Logistic回归来做分类问题,我们想要的函数应该是,能接受所有的输入然后预测出类别。例如,在两个类的情况下,上述函数输出0或1。例如海维塞德阶跃函数 (Heaviside step function),也称为单位阶跃函数。
海维塞德阶跃函数的问题在于: 该函数在跳跃点上从0瞬间跳跃到1(不连续、不可微),这个瞬间跳跃过程有时很难处理。但是在数学上,Sigmoid函数可以可以解决这个问题。Sigmoid函数具体的计算公式如下:
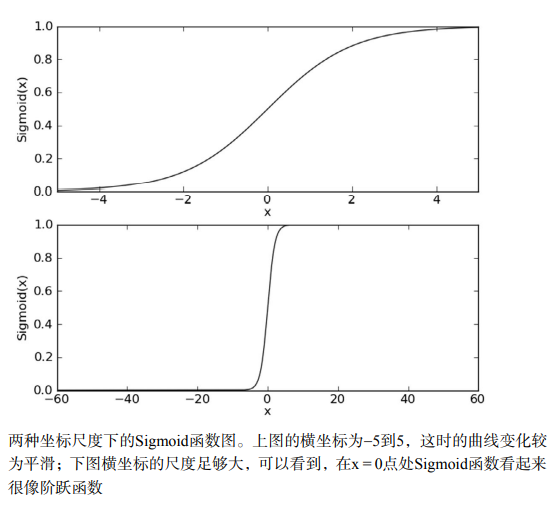
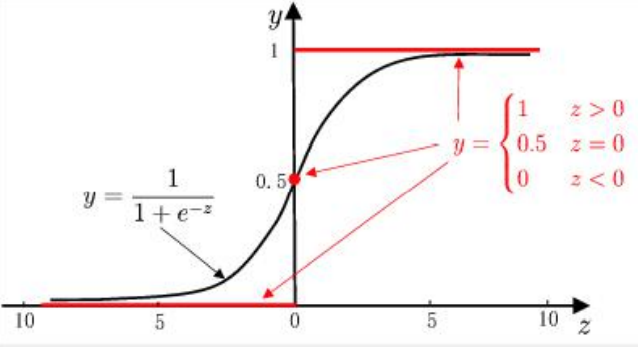
下图给出了Sigmoid函数在不同坐标尺度下的两条曲线图。当x为0时,Sigmoid函数值为0.5。 随着x的增大,对应的Sigmoid值将逼近于1;而随着x的减小,Sigmoid值将逼近于0。如果横坐标刻度足够大,Sigmoid函数看起来很像一个阶跃函数。
所以,为了实现Logistic回归分类,我们可以在每个特征上都乘以一个回归系数,然后把所有的结果值相加,将这个总和代入Sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于0.5的数据被分入1类,小于0.5即被归入0类。所以,Logistic回归也可以被看成是一种概率估计。
预测值与输出标记: 运用Sigmoid函数:
对数几率(log odds):样本作为正例的相对可能性的对数 因此有:
上面两个式子分别表示y=1和y=0的概率。通过,我们获得z值,再通过Sigmoid函数把z值映射到0~1之间,获得数值之后就可进行分类。比如定义,大于0.5的分类为1,反之,即分类为0。所以我们要解决的问题就是获得最佳回归系数,即求解w和b得值。 Sigmoid介绍引用自此处:(57条消息) 机器学习 —— Logistic回归_DreamWendy的博客-程序员秘密_logit回归 三、模型优缺点 逻辑回归优点 1、简单、系数容易解释 2、目前应用范围很广,尤其是银行业 逻辑回归缺点 1、多分类问题效果较差 2、需要做特征筛选 四、参数介绍 参数 解释 可选值 penalty 惩罚项 默认0;L1:向量中各之和元素,常用于特征选择;L2:向量中各各元素平方和开根号,用于较多特征选择;通常选L2应对过拟合,如果L2效果不好再用L1。 solver 优化算法 liblinear、lbfgs、newton-cg、sag;后三种优化算法只能用L2惩罚项,liblinear通用。此外,大数据量优先sag,多分类优先sag、newton-cg、lbfg。 max_iter 最大迭代次数 默认100,只有lbfgs、newton-cg、sag时才能用 multi_class 指定分类策略 ovr:快,简单,较差;multinomial:慢,更准;auto:根据solver自动选择。 warm_start 是否从头开始 布尔值,默认False,如果为True使用前一次训练结果继续训练 n_jobs cpu数量 默认为1,如果为-1则使用了所有能用的cpu。 五、案例数据介绍
数据集中共有24个特征,7000个样本,从Y的值为0和1可以知道是二分类问题。这是比赛数据,非保密数据,只是我不知道怎么打包上传,如果有需要可以私信我。 六、案例建模了解参数的作用后一般逻辑回归就不需要反复调参直接确定参数跑代码就可以。 读取数据 import pandas as pd datas=pd.read_csv('data_20221030(1).csv') datas=datas[datas.columns[2:]] datas数据如上面的截图所示 模型代码 #逻辑回归 import matplotlib.pyplot as plt import matplotlib as mpl from sklearn.preprocessing import StandardScaler from sklearn.pipeline import Pipeline from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression import numpy as np x=datas.iloc[:,:-1]#包含9月还款和消费状态 y=datas['Y'] X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=1) # 用pipline建立模型 lr = Pipeline([('sc', StandardScaler()), ('clf', LogisticRegression(penalty='l2',multi_class="multinomial", solver="newton-cg"))]) lr.fit(X_train, y_train) # 测试集上的预测结果 y_hat = lr.predict(X_test) # 回归的y y = y_test.ravel() # 变一维,ravel将多维数组降位一维 result = y_hat == y # 回归的y和真实值y比较 print(y_hat) print(result) acc = np.mean(result) # 求平均数 print('准确率: %.2f%%' % (100 * acc))
在这个数据集上的效果一般,主要原因是没有做数据清洗和特征筛选的工作。 |
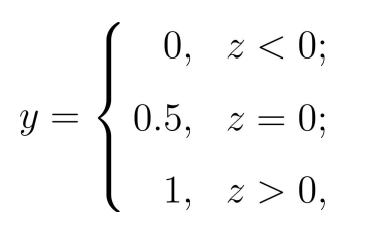
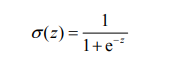
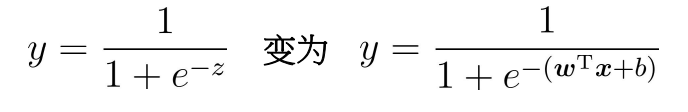


【本文地址】
今日新闻 |
推荐新闻 |